Cloudant
Querying Overview
Qarbine utilizes the IBM Cloudant node.js interface to access data withinCloudant. For querying the primary interface is a JSON-like structure which maps to the Cloudant API specification.
Cloudant has several types of indexes which can be used for querying:
- general,
- views, and
- text search (Lucene based)
Unlike traditional SQL which has a FROM TABLE clause, in most Cloudant queries an explicit index (˜ table) is optional. Cloudant selects the most suitable index based on the query’s selector fields. You can use the useIndex option in a general query to guide Cloudant.
Types of Interactions
Cloudant indexes differ in the type of data they return based on whether you use a regular index (views), a text index (Lucene-powered search), or a search index. Here’s how each type behaves:
- Views
- These are MapReduce views in design documents, where the map function emits key-value pairs.
- Returned Fields:
- key: The emit function defines the key for each result.
- value: The emit function also defines the accompanying value, which can be any JSON data.
- Including includeDocs: true returns the key’s entire document in the ‘doc’ field.
- Text Index (Lucene)
- Text indexes allow full-text search and support scoring, wildcards, and advanced querying. These are defined in design documents under the indexes key.
- Returned Fields:
- score: A numeric value indicating the relevance of the result based on the query.
- fields: Only fields explicitly indexed using the index() function in the design document are searchable. Returned data depends on the document fields included and also the {store: true} setting.
- Including includeDocs: true returns the entire document in the ‘doc’ field.
- General
- Custom search indexes combine structured and text queries, letting you filter data and perform full-text searches at the same time.
- Returned Fields:
- fields: These are explicitly indexed fields defined in the design document.
- Partial Filter: Results may include only documents satisfying the partialFilterSelector in the index.
- Document Metadata: Includes document _id and _rev by default.
- Including includeDocs: true returns the entire document in the ‘doc’ field.
Cloudant has some index limits that you can review online. For example, indexes are limited to 200 results when queried. The default is 25. Also, all sorting fields must use the same sort direction, either all ascending or all descending.
Besides these Cloudant queries there are Qarbine virtual query statements described below.
Native Query Specification
The native query specification for Cloudant is a JSON structure. Below is an example.
{
qType: 'search',
ddoc: 'searchBooks',
index: 'by_descriptions',
includeDocs: true,
query: 'long:"querying"',
}
The optional qType key provides Qarbine guidance on which Cloudant API call to make. Its value may be index, search, text, or view. In some cases it can be inferred by the presence of another key. For example, ‘view:x’ for a view interaction or ‘query:x’ for a search interaction.
The keys and values correspond to those described in the table below.
The “db” key of the query specification will be filled in automatically if none is set based on the Data Source Designer’s database drop down’s selection. If the data service has a database set then it is the secondary default.
Operators
Only equality operators such as $eq, $gt, $gte, $lt, and $lte (but not $ne) can be used as the basis of a query. You should include at least one of these in a selector.
Some operators such as $not, $or, $in, and $regex cannot be answered from an index. For query selectors use these operators in conjunction with equality operators or create and use a partial index to reduce the number of documents that will need to be scanned.
For more information see https://cloud.ibm.com/docs/Cloudant?topic=Cloudant-operators.
Controlling Which Fields are Returned
A search query has “includeDocs: boolean” and “includeFields: Array” options. See
https://cloud.ibm.com/docs/Cloudant?topic=Cloudant-cloudant-search
An index query has a “fields:Array” option. If not defined or empty then the whole document is returned. Here are some examples.
fields: [ 'name' , 'age'],
fields: [ '*' ] ← Returns the whole document.
A view’s fields are defined in the view’s design document definition.
Data Conversions
JSON Handling
Qarbine automatically returns native JSON objects back in the answer set. There is no flattening of JSON objects into simple JSON strings.
Manipulating Answer Set Row Shape (Pragmas)
Qarbine has many “pragmas” for manipulating answer set rows. These are described in more detail in the main Data Source Designer document. Of specific relevance to Cloudant are the pullFieldsUp and convertToDate pragmas.
The searchCustomerStored search index below was defined with
index('name', doc.name, {store: true} );
index('email', doc.email, {store: true} )
Running this query specification
{
"db": "customers",
"limit": 25,
"ddoc": "searchCustomerStored",
"index": "by_name_email_stored",
"query": "*:*",
}
results in a row looking like
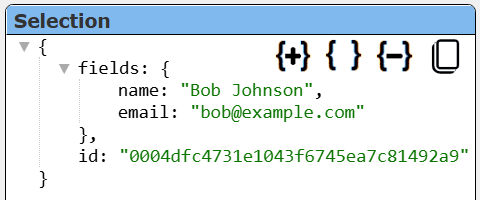
After adding the !arbine pragma line shown below
#pragma pullFieldsUp fields
{
"db": "customers",
"limit": 25,
"ddoc": "searchCustomerStored",
"index": "by_name_email_stored",
"query": "*:*",
}
the results are

Having the name and email at the root level of the JSON object makes it easier to review the query results and interact within a template.
If full documents are returned via the ‘doc’ field then this pragma line may be of use.
#pragma pullFieldsUp doc
With views which emit a ‘value’ field this pragma may be of use,
#pragma pullFieldsUp value
Date Handling
Cloudant returns dates as ISO formatted strings such as "2025-04-25T14:44:29.854Z".
You can have these strings converted into real Dates using the Qarbine pragmas
#pragma convertToDate CSV_FIELD_NAMES
For example the following query specification
//#pragma deleteFields fields
{
"db": "ecommerce",
"limit": 25,
// selector: { title: "Android in Action, Second Edition" }
selector: { publishedDate: "2011-01-14T08:00:00.000Z" },
fields: [ 'title' , 'publishedDate']
// fields: [ 'title' , 'publishedDate', 'shortDescription']
}
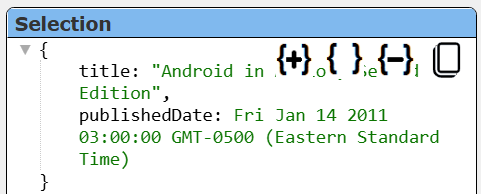
returns a row with a simple ISO string for publishedDate looking like.

Adding
#pragma convertToDate publishedDate
returns a row with a real Date object looking like.
Queries to Cloudant with date values also use the ISO string representation. For example,
{
db: 'myDatabase',
selector: {
timestamp: { "$gt": "2025-04-01T00:00:00.000Z" }
}
Debugging Queries
Qarbine has several default interactions to help understand how queries are being formatted and run. For example, there may be variables or macro expressions in a query specification and you would like to use the final query which would be sent to the database. This can be done in the Data Source Designer by pressing Alt and then the run icon. Another option is to include the following in the JSON query specification.
If you want to gain knowledge of the database’s view of the query the SQL EXPLAIN clause would work in standard SQL databases. For Cloudant you can add the following line to the JSON query specification.
whichIndex: true
This function as described at https://cloud.ibm.com/apidocs/cloudant?code=node#postexplain.
Qarbine Virtual Queries
There are a few convenience queries which are mainly DBA oriented. These queries are recognized by the Qarbine driver and provide common database information. Any catalog and schema set in the data service definition constrain what is returned. For example, if a catalog is given in the data service, then only schemas in that one catalog are returned.
These virtual query defaults are independent of whatever drop down option is chosen in the Data Source Designer tool. If a specific schema’s information is wanted for example, it must be explicitly given.
| Query | Description |
|---|---|
| describe server | Return details on the Cloudant server. |
| list databases | Return a list of database names. |
| describe database [DATABASE] | Return the details of the given database. If one is specified in the data service then use that as the default. |
| list indexes [DATABASE] | Return a list of index names. Optionally provide a database context. |
| describe index INDEX [DATABASE] | Provide details of the given index. Optionally provide a database context. |
| describe design documents [DATABASE] | Provide details of all of the design documents of the given database. If one is specified in the data service then use that as the default. |
Index Naming Conventions
In the Qarbine querying tools there are drop downs for the data service, database and collection (AKA index). Below is a Data Source Designer snippet.

Below is a picture of the collections drop down contents.
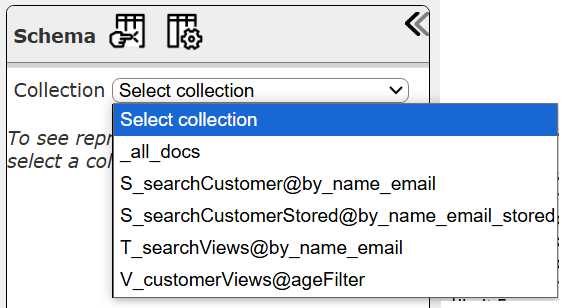
Except for “_all_docs”, the format of the collection (AKA table) names is
prefix designDocumentId @ indexName
The prefix provides indirect guidance on the retrieval options available. The table below cross references the prefixes to their index type.
| Prefix | Index Type |
|---|---|
| I_ | Index |
| S_ | Search |
| V_ | View |
| ?_ | Unknown |
Qarbine SQL Querying
Overview
Qarbine provides a SQL oriented option to retrieve Cloudant data. This interface interacts with a single index at a time and provides full access to Cloudant’s underlying retrieval features. It can be much easier to author WHERE clause criteria using SQL syntax than the JSON structure of native Cloudant.
SELECT Clause
Below are some common patterns and their uses.
| Pattern | Description |
|---|---|
| select * | Returns the default fields based on the native definition of the query. |
| select foo, bar | Returns the listed fields. This maps to the includeFields: or fields: setting of the query specification. Any fields that are included in the SELECT must be indexed with the store:true option. |
| select *, document | Returns the fields plus sets the includeDocs flag to true. Note that “document” is case sensitive. |
| select document | Sets the includeDocs flag to true. |
FROM Clause
The table name in the from clause is either
- _all_docs or
- prefix designDocumentId @ indexName.
The second option’s value must be enclosed in single quotes, double quotes, or tick marks. Only a single table can be referenced.
WHERE Clause
The WHERE clause is constrained by the underlying platform operators and retrieval features. Standard operators such as = and <= are translated into their Cloudant specific syntax.
Qarbine provides several convenience functions to assist in the SQL oriented querying.
| Function | Description |
|---|---|
| withOption(...) | Pass in the specification field name to set and the value. This clause is removed from the WHERE clause. This is a way to set a query specification field that is not readily translated from the SQL world. See the section below for more details. |
| withOptions(...) | Set several specification fields at once. The format is withOptions(key1, value1, keyN, valueN) The key argument may use dot notation when setting the inner value of a component object. See the section below for more details. |
| list(values 0 … n) | This is a convenience function primarily to be used alongside withOption() and withOptions() when the value for a key must be a list of some sort. See the sort example below. |
| searchText(LuceneCriteria) | This is used for search oriented retrievals and sets the query property of the Cloudant query specification. |
ORDER BY Clause
You can use the standard SQL ordering syntax as shown below.
order by pageCount
Alternatively you can use the withOption() or withOptions() functions to set a query specification field to a value. This is described in the next section.
For search index retrievals the default sort order is a numeric comparison. To sort by a string end the column name with “_string”. So “order by foo_string” ends up in the low level Cloudant query specification as “foo<string>”. String fields that are used for sorting must not be analyzed. Fields that are used for sorting must be indexed by the same indexer that is used for the search query. For more details see the ‘sort’ parameter discussion at https://cloud.ibm.com/apidocs/cloudant?code=node#postsearch.
Setting Other Query Property Fields
These WHERE clause functions provide a way to set query specification properties which do not map well to the nature of SQL but satisfy the syntax of SQL. The function are:
withOption(name, value);
withOptions(name1, value1, nameN, valueN);
The following example uses the Qarbine List() SQL function to create a list of values. That list is then set as the ‘sort’ property in the query specification.
withOption('sort', list('pageCount') )
Another approach is to take into account that if the value is a string which looks like a JSON object (starts with “[“ or “{“) then a conversion will be made to determine the value prior to setting the property in the query specification.
withOption('sort', '[pageCount]' )
LIMIT Clause
Any value here sets the “limit : ###” portion of the native Cloudant query specification.
Answer Set Manipulation
Qarbine pragmas were mentioned above. To further that discussion here are some useful combinations.
This set of pragmas copies the retrieved document title and thumbnailUrl values up as root level values. It then removes the doc and fields properties from the document. Once done the final answer set is passed along the execution flow for display, template processing, or other use. This can dramatically reduce the size of the answer set sent from the Qarbine server to the web browser.
pragma pullValuesUp doc.title, doc.thumbnailUrl
#pragma deleteFields fields, doc
To bring all of the fields of the retrieved document to the root level you can use the following.
#pragma pullFieldsUp doc
Blending JSON and SQL
There are techniques to blend the ease of using SQL along with the powerful features of Cloudant within a Qarbine JSON specification object. The table below lists the fields that drive this definition.
| JSON Field | Description |
|---|---|
| sql | The SQL statement can affect the query specification as described above. |
| sqlWhere | The string can affect mainly the filtering options above. |
Here is a simple example of combining the SQL and query specification approaches. The effective result is the same as the example query specification above.
{
qType : "search",
ddoc: 'searchBooks',
index: 'by_descriptions',
limit: 25,
sqlWhere: "searchText('long:\"querying\"')",
includeDocs: true,
}
Note that for the Lucene criteria in the searchTex() function the inner double quotes are prefixed by a slash. Here is another version that yields the same underlying Cloudant request.
{
qType : "search",
ddoc: 'searchBooks',
index: 'by_descriptions',
sql: "select document from someWhere where searchText('long:\"querying\"') limit 25",
}
The qType, ddoc, and index values provide the context for the type of index interaction. Valid case sensitive qTypes are ‘search’, ‘index’, and ‘view’. It provides context in a similar manner as the index prefixes (i.e., “S_”). The sql argument’s “someWhere” reference is effectively ignored.
Sample Lucene Queries
Below are examples of complex Lucene queries you can use with Cloudant's search functionality. Note that the range’s ‘TO’ keyword must be uppercase!
Wildcard Search
Search for documents where the description field starts with "hel" (e.g., "hello", "help"):
description:hel*
Boolean Operators
Combine multiple conditions using AND, OR, and NOT:
description:hello AND type:example
- Matches documents where description contains "hello" and type is "example".
Range Queries
Search for documents within a specific range of dates:
created_date:[2023-01-01 TO 2023-12-31]
- Matches documents where created_date falls between January 1, 2023, and December 31, 2023. In Cloudant the “TO” is case sensitive!
Phrase Search
Search for an exact phrase in the description field:
description:"exact phrase"
- Matches documents where description contains the exact phrase "exact phrase".
Faceted Search
Group results into categories based on a field (e.g., price ranges):
*:*&ranges={"price":{"cheap":"[0 TO 100]","expensive":"{100 TO Infinity}"}}
- Categorizes documents into "cheap" and "expensive" based on the price field. In Cloudant the “TO” is case sensitive!
Proximity Search
Find documents where words appear close to each other:
description:"cloud database"~5
- Matches documents where "cloud" and "database" appear within 5 words of each other in the description field.
Boosting
Prioritize documents with specific terms:
description:cloud^2 database
- Boosts documents where description contains "cloud" over those containing "database".
Filtering by Multiple Fields
Search for documents matching multiple fields:
author:Doe AND publisher:Penguin AND year:[2000 TO 2023]
- Matches documents where author is "Doe", publisher is "Penguin", and year is between 2000 and 2023. In Cloudant the “TO” is case sensitive!
Excluding Terms
Exclude documents containing specific terms:
description:cloud NOT database
- Matches documents where description contains "cloud" but not "database".
Numeric Range Queries
Search for documents with numeric values in a specific range:
price:[10 TO 50]
- Matches documents where price is between 10 and 50. In Cloudant the “TO” is case sensitive!
Troubleshooting
Some queries can be reviewed using the Cloudant Dashboard. Sign on to IBM Cloud and navigate to your database.

On the right hand side click

Select your database.
Click Query

Enter your native Cloudant query.
Click

You can obtain the final Cloudant query specification by pressing the Alt key and clicking  .
.
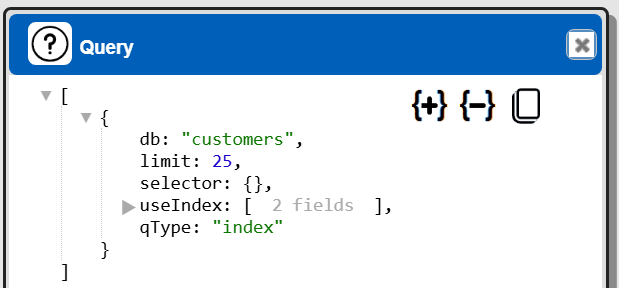
Copy the content by clicking

Close the dialog by clicking

Paste the clipboard into the Cloudant Dashboard.

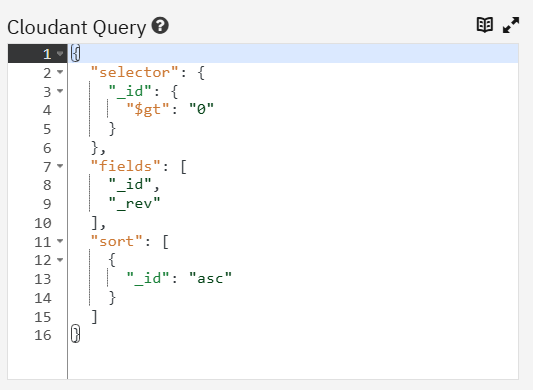
Remove the qType line, db line, and the enclosing brackets “[“ and “]”. The content must be valid JSON.
The dashboard uses non-camelcase field names which is different from the node.js interface that Qarbine uses. You need to change keys such as “useIndex” into “use_index”. Otherwise this type of error occurs.

Here is an adjusted Cloudant query.

References
https://cloud.ibm.com/docs/Cloudanthttps://cloud.ibm.com/docs/Cloudant?topic=Cloudant-cloudant-search